Disclaimer
Diese Einführung basiert auf einem Artikel, der unter https://www.ernstlx.com/linux90linux.html verfügbar ist. Einige Abschnitte sind direkt von dort übernommen, andere habe ich grundlegend überarbeitet oder neu ergänzt.
Einführung: Das Betriebssystem Linux
Genau genommen ist Linux gar kein Betriebssystem, sondern nur ein Kernel, also der Teil des Betriebssystems, der direkt mit der Hardware kommuniziert und dessen Funktionen den Benutzerapplikationen über abstrakte Schnittstellen zur Verfügung stellt. Linus Torvalds startete 1991 die Entwicklung des Linux-Kernels und stellte seinen Code 1992 der Welt als Freie Software unter der GNU Gerneral Public License (GPL) zur Verfügung. Dadurch begannen auch viele andere Entwickler, daran mitzuarbeiten. Heute ist das Linux-Kernel eines der größten Software-Projekte überhaupt und wird von Freiwilligen, sowie Angestellten sämtlicher großer Tech-Konzerne unter der Leitung von Linus Torvalds stetig weiterentwickelt.
Spricht man heutzutage von Linux, ist allerdings in der Regel nicht nur das Kernel gemeint, sondern das gesamte darauf aufbauende Betriebssystem. Dies werde ich im weiteren Verlauf dieses Artikels ebenfalls so handhaben. Im praktischen Einsatz tritt dieses Betriebssystem meist in Form sogenannter Linux-Distributionen auf, in denen der Linux-Kernel und verschiedene Software zu einem fertigen Paket zusammengestellt sind.
Linux ist das am weitesten verbreitete Betriebssystem. Es dominiert den Servermarkt, bedient mit Android den Großteil aller Smartphones und die allermeisten ‘Smart’-irgendwas-Geräte verwenden Linux. Lediglich auf dem Desktop begnügt es sich mit einem Marktanteil von derzeit vier Prozent. Meiner Einschätzung nach liegt das in erster Line am Default-Effekt und den gigantischen Marketing-Budgets, die Microsoft und Apple zur Verfügung haben. Denn in Punkto Benutzerfreundlichkeit müssen sich Linux-Systeme mit aktuellen Desktop-Environments neben der Konkurrenz wahrlich nicht verstecken.
Aufbau des Betriebssystems
Das zentrale Kernstück des Betriebssystems, der Linux-Kernel (meist nur Kernel genannt) bildet eine Trennschicht zwischen Hardware und Anwenderprogrammen. Das heißt, wenn ein Programm auf ein Stück Hardware zugreifen will, so kann es niemals direkt darauf zugreifen, sondern nur über das Betriebssystem.
Dazu bedient sich das Programm der Systemaufrufe. Über den Systemaufruf teilt das Anwenderprogramm dem Betriebssystem mit, dass es etwas zu tun gibt. Will etwa ein Programm eine Zeile Text auf dem Bildschirm ausgeben, so wird ein Systemaufruf gestartet, dem der Text übergeben wird. Das Betriebssystem erst schreibt ihn auf den Bildschirm.
Auf der anderen Seite muss das Betriebssystem die Möglichkeit haben, mit den einzelnen Hardware-Komponenten zu sprechen. Mittels seiner Treiberschnittstelle spricht es spezielle Geräte-Treiber an. Erst die Treiber kommunizieren dann direkt mit den Geräten.

Zu den Anwenderprogrammen zählen alle von uns gestarteten Programme (Videoplayer, Webbrowser …), wie auch die grafische Oberfäche des Betriebssystems, das Desktop-Environment. Letzteres ist nicht ein Programm, sondern eine Sammlung von Programmen, die zusammen die gewohnten Funktionalitäten beisteuern.
Ein ganz spezielles Anwenderprogramm ist die Shell - die “Benutzeroberfläche”. Es existieren viele verschiedene Shells - wir werden hier mit der Bash (Bourne again shell) arbeiten. Diese ist die Standardshell auf Linuxsystemen. Alle Shells stellen dem Benutzer eine Kommandozeile zur Verfügung, mit der Befehle eingegeben werden können, die direkt als Systemaufrufe an das Betriebssystem weitergeleitet werden.
Linux ist ein Multitasking-Betriebssystem: das heißt, es können mehrere Prozesse - so nennt man Programme, sobald sie in den Speicher geladen sind und laufen - gleichzeitig laufen. Das bedingt, dass das System die verfügbare Rechenzeit des Prozessors in kleine Zeitscheiben aufteilt (im Millisekundenbereich), die dann den jeweiligen Prozessen zur Verfügung stehen. Diese Aufgabe übernimmt eine übergeordnete Instanz - der Scheduler. Dieser verwaltet die Zuteilung der Zeitscheiben an die verschiedenen Prozesse.
Daher kann kein Prozess die ganze Rechenleistung für sich beanspruchen und auch ein “hängender” Prozess kann nicht das ganze System lahmlegen.
Die Benutzer
Linux ist auch ein Multiuser-System, das heißt, es können mehrere Benutzer an verschieden Terminals auf dem selben Rechner arbeiten. Dazu ist es natürlich notwendig, dass jeder Benutzer eindeutig identifiziert ist. Die User (engl., Benutzer) werden zwar mit ihren Namen verwaltet, intern arbeitet ein Unix-System aber mit Usernummern. Jeder Benutzer hat also eine Nummer welche UserID oder kurz UID genannt wird. Jeder Benutzer ist auch Mitglied mindestens einer Gruppe. Es kann beliebig viele Gruppen in einem System geben und auch sie haben intern Nummern (GroupID oder GID). Im Prinzip sind Gruppen nur eine Möglichkeit, noch detailiertere Einstellungsmöglichkeiten zu haben, wer was darf.
Eine spezielle Rolle hat der Benutzer mit der UserID 0 - er ist Root (engl., Wurzel). Root steht außerhalb aller Sicherheitseinrichtungen des Systems - kurz - er darf alles. Er kann mit einem Befehl das ganze System zerstören, er kann die Arbeit von Wochen und Monaten löschen usw. Aus diesem Grund meldet sich auch der Systemverwalter im Normalfall als normaler Benutzer an - zum Root-Benutzer wird er nur dann, wenn er Systemverwaltungsarbeiten abwickelt, die diese Identität benötigen.
Die Dateien
Datei- und Verzeichnisnamen können bis zu 255 Zeichen lang sein. Dabei wird in jedem Fall zwischen Groß- und Kleinschreibung unterschieden. Die Dateinamen
- DATEI
- datei
- Datei
bezeichnen drei unterschiedliche Dateien. Ein Dateiname darf beliebig viele Punkte enthalten, also zum Beispiel auch Datei.Teil.1.txt. Ein Punkt gilt als normales Zeichen in einem Dateinamen. Dateien, die mit Punkt beginnen, gelten als versteckt und werden normalerweise nicht angezeigt - zum Beispiel .datei. Das Zeichen zum Trennen von Verzeichnis- und Dateinamen ist der Slash ("/") statt dem Backslash ("") bei Windows.
Es gibt verschiedene Dateiarten: (in Klammer die offizielle Darstellung, wie sie symbolisiert werden)
- Normale Dateien (-)
- Verzeichnisse (d)
- Symbolische Links (l)
- Blockorientierte Geräte (b)
- Zeichenorientierte Geräte (c)
- Named Pipes (p)
Wir sehen hier schon, dass auch Verszeichnisse bloß eine bestimmte Dateiart sind. Eine spezielle nämlich, in der andere Dateien aufgelistet sind. Mit einem Dateibrowser (von Windows kennen wir “Explorer”, bei Apple den “Finder”) sehen wir uns immer nur genau diese Verzeichnisse an, sofern wir nicht mittels verschiedener Plugins die Dateien selbst auswerten und Textdokumente, Bilder anzeigen oder Videos und Musik wiedergeben.
In einem Unix-Dateisystem hat jede einzelne Datei jeweils einen Eigentümer und eine Gruppenzugehörigkeit. Neben diesen beiden Angaben besitzt jede Datei noch einen Satz Attribute, die bestimmen, wer die Datei wie benutzen darf. Diese Attribute werden dargestellt als “rwx”. Dabei steht r für lesen (read), w für schreiben (write) und x für ausführen (execute).
Das Dateisystem
Das Dateisystem ist die Ablageorganisation auf einem Datenträger eines Computers. Um die Funktionsweise zu verstehen, betrachten wir einen Datenträger, die Festplatte, näher:
Die Festplatte besteht aus mehreren Scheiben mit einer magnetisierbaren Oberfläche, auf die die Schreibköpfe unsere Daten als Einsen (ein) und Nullen (aus) abspeichern. Um diese aber vernünftig adressieren zu können, benutzen wir Dateisysteme. Ein solches teilt die Festplatte (eigentlich die “Partition”, denn die Festplatte wird häufig in mehrere Partitionen aufgeteilt, die dann unabhängig formatiert werden können) in kleine Einheiten, die “Blöcke”, welche aus Performancegründen häufig noch zu “Clustern” zusammengefasst werden.
Der Block (oder Cluster) ist dann die kleinste Einheit, in die eine Datei geschrieben wird, jede Datei benötigt dadurch immer diesen Speicherplatz (oder ein vielfaches) auf der Festplatte.
Es gibt eine Vielzahl unterschiedlicher Dateisysteme. Die meisten davon werden von Linux unterstützt (siehe Wikipedia). Das NTFS von Windows und das HFS+, das Apple-Geräte verwenden, kommen unter Linux meist nicht zum Einsatz. Hier ist aktuell ext4 (*Fourth Extended File System) der Standard, wobei btrfs auch zunehmend an Popularität gewinnt. Btrfs ist deutlich neuer und ein Copy-on-write-Dateisystem. Das bedeutet, dass es beim Kopieren von Dateien erst eine tatsächliche Kopie anlegt, wenn eine der beiden Dateien verändert wird. Weitere Copy-on-write-Dateisysteme sind zfs und das ganz neue bcachefs. Sie unterstützen fancy features wie Snapshots, Subvolumes oder Transfer übers Netzwerk, sind aber z.B. im Datenbankbetrieb nicht so performant wie traditionelle Dateisysteme wie ext4 oder XFS.
Die Grafische Benutzeroberfläche
Früher wurde die grafische Benutzerpberfläche unter Linux vom X11-Server gerendert und bereitgestellt. Dieser ist allerdings älter als das Linux-Kernel selbst und weil der Code inzwischen so unwartbar ist, arbeiten die Entwickler von X11 (und inzwischen auch einige neue) seit 2008 daran, dieses durch Wayland zu ersetzen. Anders als bei X11 gibt es hier nicht den einen Server, auf dem alles aufbaut, sondern Wayland selbst ist nur eine Ansammlung von Protokollen, die von jedem Wayland-Compositor implementiert werden. Windowmanager und Desktops können also entweder, alle Wayland-Protokolle selbst implementieren, ein Library wie wlroots oder smithay dafür nutzen, oder auf dem Windowmanager eines anderen Projektes aufbauen.
Um Grafische User Interfaces (GUIs) zu erstellen, bedient man sich normalerweise eines Toolkits. Unter Linux die meistgenutzten sind hier GTK und QT. GTK wurde von GIMP ins Leben gerufen, wird aber inzwischen hauptsächlich von GNOME entwickelt. QT ist auch auf anderen Betriebssystemen ein weit verbreitetes Toolkit und wird von KDE genutzt.
Die Verzeichnisstruktur
Während unter Windows jedes logische oder physikalische Laufwerk (Festplattenpartitionen oder Geräte wie CD-Laufwerk) seinen eigenen Dateibaum, ausgehend vom Laufwerksbuchstaben hat, gibt es unter UNIX-Systemen nur einen Dateibaum, ausgehend vom Wurzelverzeichnis (am Anfang einer bestimmten Festplattenpartition), in den die anderen Laufwerke an beliebiger Stelle eingehängt werden können. Sie sind sozusagen nur Äste des einen Dateibaums.
Nun wollen wir diesen Dateibaum einmal näher betrachten. Linux hat, wie jedes Unix-System, einen sehr genau vorgeschriebenen Dateibaum. Die wichtigsten Verzeichnisse heißen immer gleich, so dass es beinahe egal ist, mit welchem Unix wir arbeiten. Wir werden uns überall zurechtfinden.
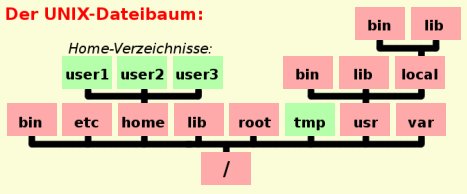
Das Wurzelverzeichnis /
Wie bereits gesagt hat Linux nur einen Dateibaum. Eine Partition (bzw. ein Laufwerk) ist also die sogenannte root-partition (Wurzelpartition). Alle anderen Partitionen und Laufwerke (auch CD-Laufwerk, USB-Stick, externe Festplatte) werden an beliebigen Stellen in den Wurzeldateibaum “montiert” (mounted).
In diesem Wurzelverzeichnis darf neben den Verzeichnissen nur eine einzige normale Datei liegen, nämlich der Kernel. Aber auch dies ist auf modernen Systemen nicht mehr der Fall, da der Kernel in das Verzeichnis /boot ausgelagert ist. Im Wurzelverzeichnis befindet sich stattdessen ein symbolischer Link auf den Kernel.
Das Verzeichnis /bin
Hier liegen Binaries, also binäre Programme, jedoch nur jene, die für die wichtigsten Arbeiten am System benötigt werden. Alle User haben in diesem Verzeichnis Lesezugriff.
Das Verzeichnis /boot
Hier liegt der Linux-Kernel und alle Dateien, die er zum Starten benötigt. Nur der root-Benutzer hat auf dieses Verzeichnis Zugriff.
Das Verzeichnis /dev
Hier liegen die Gerätedateien. Gerätedateien sind Schnittstellen zum Kernel, die ein bestimmtes Gerät bezeichnen. Unter Unix ist fast jedes Stück Hardware mit einer solchen Gerätedatei ansprechbar. Wichtig ist, dass diese Dateien keinen physikalischen Platz auf der Platte brauchen.
Das Verzeichnis /etc
Hier sind alle systemweit gültigen Konfigurationsdateien (Netzwerk, Bootmanager, Sytemstartscripts, …) abgelegt, sowie die Dateien für die Benutzerverwaltung (z.B. “passwd” und “shadow” mit den Benutzern und ihren Passwörtern).
Viele Prozesse müssen diese Dateien lesen können, um bestimmte Informationen zu bekommen. Daher muss das Verzeichnis für alle User lesbar sein.
Das Verzeichnis /home
Jeder User, den das System kennt, hat ein eigenes Verzeichnis, das in der Regel den gleichen Namen trägt, wie der User selbst. Wir nennen solche Verzeichnisse die “Home-Verzeichnisse” der Benutzer. Sie liegen alle (außer dem vom Systemverwalter “root”) im Verzeichnis /home. Nach dem Einloggen (Anmelden beim System mit Username und Passwort) befinden sich alle User immer in ihrem Home-Verzeichnis.
Innerhalb des eigenen Home-Verzeichnisses darf ein User in der Regel alles machen - auch Dateien anlegen, löschen und verändern. Außerhalb seines Verzeichnisses hat ein normaler Benutzer meist nur Leserechte - verändern, anlegen oder löschen darf er dort nicht.
Das Verzeichnis /lib
Hier liegen die Libraries, die Systembibliotheken von Unix. Dabei handelt es sich sowohl um statische Bibliotheken für das System, als auch um dynamische, die in etwa funktionieren wie die DLLs von Windows.
Die Verzeichnisse /mnt und /media
In diesen Verzeichnissen finden sich Unterverzeichnisse, die zunächst eigentlich leer sind. Sie dienen dazu, gemountete Laufwerke und Geräte einzubinden.
Ein Beispiel: in /mnt/datenarchiv könnte eine zweite, im System verbaute Festplatte eingehängt sein und unter /media/cdrom0 finden wir sehr wahrscheinlich unser (erstes) CD/DVD-Laufwerk.
Beide Verzeichnisse erfüllen den gleichen Zweck und die Verwendung ist uneinheitlich, aber meist werden in /media Wechchseldatenträger und alle erst nach Systemstart vom Benutzer eingehänten Dateisysteme (wie externe Festplatten und USB-Sticks) verwaltet.
Das Verzeichnis /proc
Auch dieses Verzeichnis benötigt keinen Platz auf der Platte, es enthält Informationen, die das laufende System ständig auffrischt. Es sind eigentlich keine Dateien und Verzeichnisse, die hier liegen, sondern Informationen des Kernels.
Das Verzeichnis /root
Dies ist das Home-Verzeichnis des Systemverwalters “root”. Warum ist dieses Verzeichnis aber nicht im Verzeichnis /home? Ganz einfach: /home ist häufig als eigene Partition implementiert. Diese Partition wird aber erst während des Systemstarts eingehängt (gemounted). Falls es zu einem Fehler kommen sollte, muss der Systemverwalter das System starten können ohne alle Partitionen einzuhängen. Es muss also auf dem Wurzelverzeichnis bereits ein arbeitsfähiges System bereitstehen. Zu einem arbeitsfähigen System gehört aber unbedingt das Home-Verzeichnis. Daher liegt das Home-Verzeichnis von “root” direkt auf der Wurzel und in der selben Partition.
Das Verzeichnis /sbin
Wie schon in /bin liegen auch hier Binaries, allerdings solche, die hauptsächlich der Systemverwalter benutzt - “System-Binaries”, sozusagen.
Das Verzeichnis /tmp
In diesem Verzeichnis werden, wie schon der Name vermuten lässt, temporäre Dateien abgelegt, die nach Verwendung nicht mehr benötigt werden. Alle Benutzer müssen hier schreiben können, aber es ist kein guter Ort, um seine Daten sicher zu verwahren. Der gesamte Inhalt wird nämlich normalerweise beim Neustart des Systems gelöscht.
Das Verzeichnis /usr
Dieses Verzeichnis enthält alle wichtigen Programme, die das System anbietet. “usr” steht dabei nicht, wie irrtümlich häufig angenommen für “User”, sondern für “Unix System Resources”.
Als Unterverzeichnisse finden wir hier analog zur Wurzel /usr/bin, /usr/lib und /usr/sbin und ihre Bedeutung entspricht jeweils denen des Wurzelverzeichnisses. Einige weitere wichtige Unterverzeichnisse wollen wir noch näher betrachten:
/usr/local dient der Trennung von distributionseigenen und fremden, zusätzlich installierten Programmen. Unter /usr/local finden wir nochmals die gleichen Verzeichnisse wie im Verzeichnis /usr selbst. Selbst kompilierte Programme sollten immer in /usr/local installiert werden und nie direkt in /usr und die Konfigurationsscripts der Programme sehen dies meist auch als Default vor.
/usr/share beinhaltet architekturunabhängige Daten, die verschiedene Programme zum Betrieb benötigen und die nicht verändert werden.
/usr/src enthält die Quelltexte für alle Programme des Standardsystems.
Das Verzeichnis /var
Dieses Verzeichnis beinhaltet Daten, die von Programmen häufig neu geschrieben werden müssen. Ursprünglich waren diese Daten auch unter /usr zu finden, aber der Wunsch /usr auch schreibgeschützt mounten zu können machte eine Trennung notwendig. Hier werden auf einem Mailserver Mails zwischengelagert (/var/spool) und alle Programme schreiben hierher ihre Log-Dateien (/var/log).
Wir werden auch noch einige andere Verzeichnisse und Unterverzeichnisse finden, die teilweise leer sind oder nur symbolische Links in andere Verzeichnisse enthalten und häufig aus Kompatibilitätsgründen existieren. Ein Verzeichnis sei vielleicht noch erwähnt:
Das Verzeichnis /opt
Dieses Verzeichnis ist eine Linux-Erfindung. Nachdem immer mehr große Programmpakete installiert wurden, gab es die Überlegung, diese nicht mehr in das Verzeichnis /usr zu packen, sondern ein eigenes Verzeichnis dafür zu schaffen. Tatsächlich nutzen nur wenige Programme von sich aus diese Möglichkeit und auf vielen Systemen bleibt dieses Verzeichnis leer.
Die Linux-Distributionen
Eine Linux-Distribution ist ein Paket aus Kernel und diversen darauf aufsetzenden Programmen, die zusammen ein Betriebssystem bilden. Da theoretisch jeder, der Lust hat, seine eigene Distributiion bauen kann, gibt es unzählige Linux-Distributionen. Eine Grafische Darstellung als Zeitleiste findet sich hier.
{kind=link}
Im folgenden möchte ich die aus meiner Sicht wichtigsten Distributionen kurz vorstellen.
Debian
Debian ist eine nicht-kommerzielle Distribution und das Debian-Projekt ist nach der Debian-Verfassung geregelt, die eine demokratische Organisationsstruktur vorsieht. Darüberhinaus ist das Projekt über den Debian Social Contract zu völlig freier Software verpflichtet. Mit einigen 1000 Mitwirkenden ist Debian der Gigant unter den Linux-Systemen.
Da bei Debian eine “stabile Version” immer eine wirklich stabile Version ist, sind die Entwicklungszeiten relativ lang und böse Zungen behaupten auch, dass die stabile Version schon bei Erscheinen veraltet ist.
Allerdings bietet Debian auch immer schon die zukünftigen Versionen an und so gibt es mehrere Zweige, aus denen man sich bedienen kann:
stable - wirklich stabile Version, die hervorragend für den Serverbetrieb geeignet ist und an der Uni Paderborn auf allen vom IRB betriebenen Servern und Poolrechnern zum Einsatz kommt.
testing - die zukünftige stable-Version. Ab einem gewissen Entwicklungsstand wird die Distribution “eingefroren” (engl. “frozen”) - d.h. es werden keine neueren Versionen von Programmen mehr aufgenommen, sondern nur noch an der Fehlerbeseitigung bei den vorhandenen gearbeitet. Dies entspricht ungefähr dem Zustand, bei dem andere Distributoren ihre “stabilen” Versionen veröffentlichen.
unstable - ist der erste Anlaufpunkt für neue Versionen von Paketen und Programmen, bevor sie in testing integriert werden. Man installiert sich mit unstable das neueste vom neuen, muss aber wissen, dass das nicht immer stabil ist.
experimental - ist kein vollständiger Zweig, denn es dient nur dazu, Programme und deren Funktionen zu testen, die sonst das ganze System gefährden würden. Es enthält immer nur die gerade getesteten, bzw. die von diesen benötigten Programmpakete.
Diese Zweige haben auch immer Codenamen und sind, einer Vorliebe der frühen Entwickler folgend, immer nach Figuren aus dem Film “Toy Story” benannt. So heißt im Moment (2024) die stable-Version “Bookworm” und “Trixie” ist testing. unstable ist immer “Sid”, der Junge von nebenan, der die Spielsachen zerstört, aber es lässt sich auch als Abkürzung für “still in development” (noch in Entwicklung) deuten.
Debian ist die Distribution mit den meisten Forks, als anderen Distributionen, die auf Debian basieren. Dazu gehören:
- Raspberry Pi OS
- Kali
- Tails
- Linux Mint Debian Edition und insbesondere natürlich
Ubuntu
Ubuntu entstand 2004 mit dem Ziel, Linux benutzerfreundlich und für jeden verfügbar zu machen. Es wird von der Firma Cannonical entwickelt und basiert auf Debian. Ubuntu vereinfachte sehr viele Dinge in Desktop-Linux und war damit so erfolgreich, dass es heute mit Abstand die am weitesten verbreitete Linux-Distribution auf dem Desktop ist. Und auch auf Servern ist Ubuntu beliebt, hier verdient Cannonical in erster Linie sein Geld.
Releases erscheinen mit schöner halbjährlicher Regelmäßigkeit und der Upgrade auf diese lässt sich ebenfalls auf Mausklick bewerkstelligen. Alle 2 Jahre gibt es eine “Versionen mit verlägerter Unterstützung” (Long Term Support oder kurz LTS), die dann deutlich stabiler als die kürzer unterstützten ist. Für EinsteigerInnen ist Ubuntu bestens geeignet.
Auch auf Ubuntu basieren zahlreiche weitere Distributionen:
- Varianten mit anderen Desktop Environments wie z.B. Kubuntu, Xubuntu und Lubuntu
- Linux Mint
- Ubuntu Touch
- KDE Neon
- PopOS
- TuxedoOS
- VanillaOS
Fedora
Das nicht-kommerzielle Fedora ist der Nachfolger des traditionsreichen, kommerziellen Red Hat Linux, welches nicht mehr selbständig weiterentwickelt wird. Statt dessen verkauft die Firma Red Hat, das auf Fedora basierende Red Hat Enterprise Linux.
Fedora ist eine sehr innovative Distribution. Gibt es grundlegende Veränderungen im Linux-Ökosystem wie z.B. die Einführung von Systemd, Pipewire oder Wayland, ist Fedora eigentlich immer unter den ersten Distributionen, die diese Veränderungen vornehmen. Einigen Leuten passieren dadurch Änderungen zu früh, wenn sie noch nicht stable sind. Trotzdem hat Fedora inzwischen eine sehr große und aktive Community, und bietet Spins mit vielen verschiedenen Desktop Enviroments an.
Distributionen für ‘Fortgeschrittene’
Wer viel über Linux lernen will, baut sich sein System am besten so weit es geht selbst zusammen. Hierfür bieten sich die folgenden drei Distributionen an, die in ihrem Wiki jeweils detailliert beschreiben, wie man das macht.
Linux From Scratch
Linux From Scratch oder LFS lässt seine Benutzer alles selbst konfigurieren und kompillieren. Es bietet den tiefsten Enblick, macht aber auch die meiste Arbeit. Soweit ich gehört habe, sollte man für die Installation etwa eine Woche einplanen und muss sich danach selbst um die Organisation und Kompilierung von (Sicherheits-) Updates kümmern.
Gentoo
Auch Gentoo ist source-based und lässt einen seine Programme selbst kompilieren. Es bietet allerdings einiges an Automatisierung wie einen eigenen package manager, die diesen Prozess und die weitere Administration gegenüber LFS deutlich vereinfacht. Soweit ich gehört habe, dauert die Installation etwa einen Tag.
Erwähnenswerte Distributionen, die auf Gentoo basieren:
- Chromium OS bzw. ChromeOS
Arch Linux
Arch Linux bietet fertig kompilierte Pakete an, so dass die Installation von Software deutlich schneller geht, als bei Gentoo oder LFS. Arch Linux wird, genau wie Gentoo und LFS, manuell auf der Kommandozeile installiert und lässt sich nahezu beliebig nach eigenen Vostellungen anpassen. Ist das System einmal eingerichtet, gibt es laufend Updates, die potentiell eine Reparatur nach sich ziehen können. Meiner Erfahrung nach passiert dies jedoch äußerst selten. Ich nutze Arch Linux persönlich auf meinem Laptop und meinem Tablet, weil ich damit immer die neueste Software bekomme und mir mein System so einrichten kann, wie ich möchte. Für die Installation veranschlage ich einen Abend.
Erwähnenswerte Distributionen, die auf Arch Linux basieren:
- Manjaro
- SteamOS
Desktop Environments
Anders als bei Microsoft und Apple gibt es bei Linux-Distributionen keinen festgelegten Desktop. Viele Distributionen bieten entweder die Möglichkeit, den Desktop zu ändern, oder sie bieten mehrere Spins oder Flavours mit unterschiedlichen Desktops an.
GNOME
GNOME ist wohl das am weitesten verbreitete Desktop-Environment unter Linux. Sowohl Ubuntu, als auch Fedora kommen standardmäßig mit GNOME, wobei Ubuntu noch einige Dinge anpasst. Wer das pure GNOME ausprobieren will, sollte also zu Fedora greifen.

GNOME zeichnet sich durch schlichtes und modernes Design aus. User Interfaces sind nicht mit Optionen überladen und von Stil her sehr einheitlich. GNOME hat einen speziellen Workflow, der stark darauf beruht, mit dem Super-Key in den oben abgebildeten Overview-Effekt zu gehen. Manche Leute lieben diesen Workflow, für andere ist er eher weniger geeignet. Das GNOME-Ökosystem bietet eine Vielzahl verschiedener Apps. Diese dienen in der Regel einem Zweck ohne sonstigen Schnickschnack und passen visuell perfekt in den GNOME-Desktop.
KDE Plasma
KDE Plasma ist das zweitgrößte Desktop-Environment unter Linux. TuxedoOS und SteamOS kommen standartmäßig mit Plasma, aber auch z.B. Ubuntu und Fedora bieten Varianten damit an.

KDE Plasma zeichnet sich dadurch aus, das man es sich anpassen kann, wie man möchte. Voreingestellt ist das oben gezeigte Layout, das vielen Windows-Usern nicht fremd sein dürfte. Aber auch der Desktop von MacOS oder GNOME lassen sich zu einem hohen Grad in Plasma amulieren, wenn man weiß, wie man die Einstellungen navigiert. Auch KDE verfügt über viele verschiedene Apps. Diese bieten meist einen größen Funktionsumfag und sind in vielen Fällen auch für Windows oder Android verfügbar. Ein paar bemerkenswerte KDE-Apps möchte ich hier besonders hervorheben:
- Krita ist eine der besten Programme, um digitale Kunst zu erstellen und muss sich nicht hinter Adobe verstecken
- Kdenlive ist der beste Open Source Video-Editor
- Okular ist ein Dokumentenbetrachter und stand 2024 die einzige Software überhaupt, die mit dem Blauen Engel ausgezeichnet ist
- KDE Connect verbindet Geräte (auch welche mit Android oder IOS) im eigenen Netzwerk und lässt einen z.B. die Zwischenablage synchronisieren, Dateien senden oder Medienwiedergabe vernsteuern
Weitere Desktop-Environments
Es gibt eine Vielzahl weiterer Desktop-Environments für Linux. Diese haben aber alle eine kleinere Community und weniger Apps als GNOME und KDE und Mitte 2024 hat auch noch keines von ihnen richtige Unterstützung für Wayland. Da ich sie außerdem selbst nie wirklich genutzt habe, spare ich mir hier weitere Ausführungen und verweise stattdessen auf diesen Post.
Windowmanager
Wer keinen vollen Desktop haben will, kann sich auch mit einem Windowmanager begnügen und alle weiteren Komponenten selbst zusammensuchen. Window Manager zeichnen sich in der Regel dadurch aus, dass sie sehr wenig Ressourcen verbrauchen, alles mögliche ins Feinste konfigurieren und automatisieren lassen und dass sie Tiling machen, also Fenster automatisch so anordnen, dass sie sich nicht überlappen. Die beiden beliebtesten Windomanager unter Wayland sind Sway und Hyprland.